このページでは、ナレッジベースへの書類の追加方法、機密度の設定、重複防止の仕組み、バージョン管理、引用の表示方法を説明します。 ナレッジベース(KB)は会社の書類を永続的に保存する場所です。エージェントは質問に答える際にここから情報を引き出し、出典を表示します。単純な埋め込み検索ではなく、3 段階の重複防止・バージョン管理・機密度分類が組み込まれています。Documentation Index
Fetch the complete documentation index at: https://docs.teeem-ai.com/llms.txt
Use this file to discover all available pages before exploring further.
概念の概要
2 段階の機密度
公開 — 組織全員が閲覧できる
非公開 — チャンネルスコープの権限設定、許可されたメンバーのみ
3 段階の重複防止
同じファイルを重複して登録しません。登録コストを削減し、検索ノイズを減らします。
バージョン履歴
新しいバージョンが古いバージョンをソフト削除します。変更履歴は保持されます。
永続的な引用
回答で使った出典は監査目的のため永続メッセージとして記録されます。
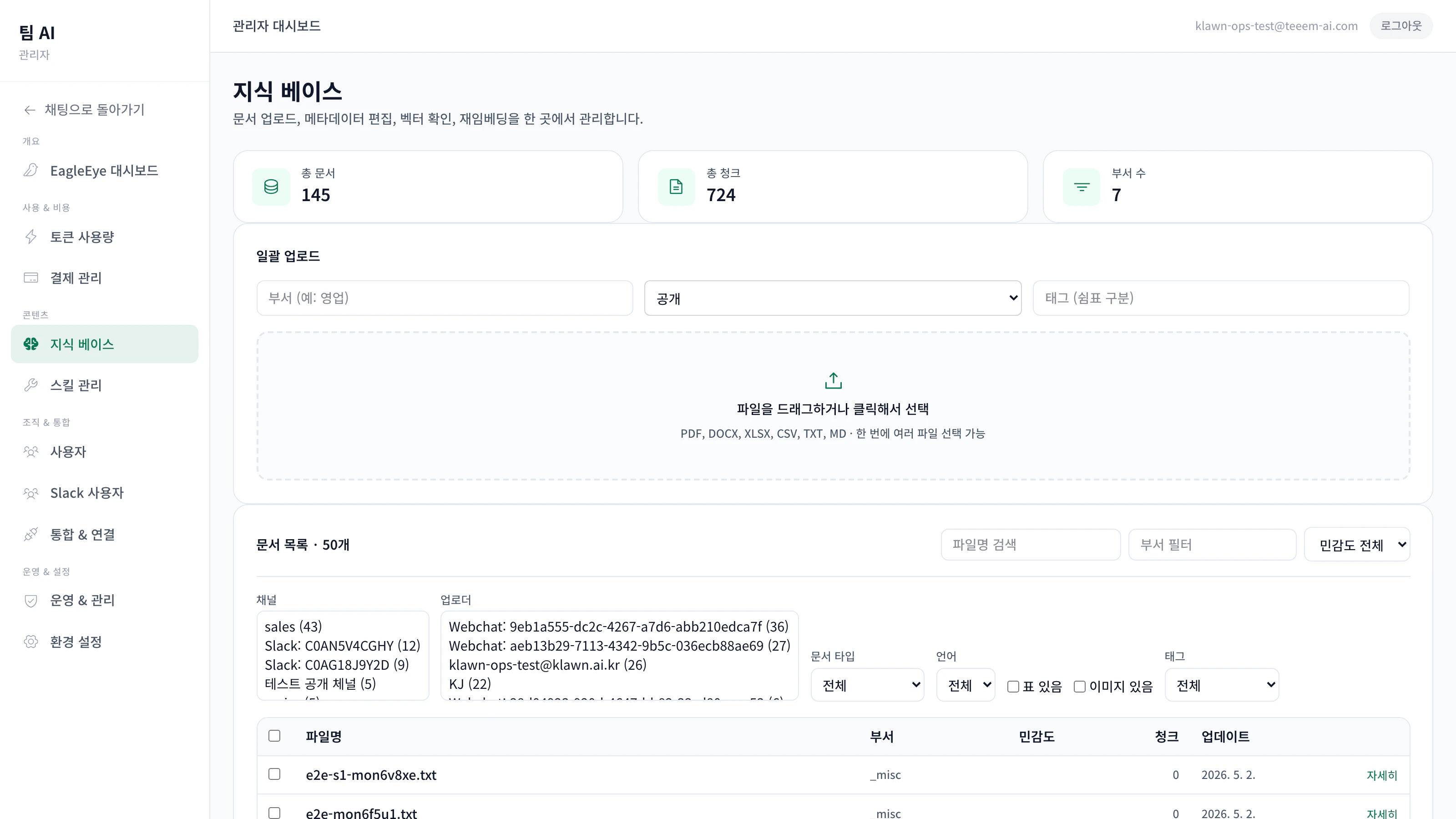
アップロードの方法
- ウェブチャット
- Slack
- 管理画面
- API
チャット入力欄にファイルをドラッグ&ドロップします。チャット上部のプログレスバーで進捗を確認できます。
機密度の段階
機密度はアップロード時に自動で分類され、管理者が後から変更できます。| 段階 | 検索・引用できるユーザー |
|---|---|
| 公開 | 組織内の全員 |
| 非公開 | 該当するチャンネル・チームのメンバーのみ(権限設定ベース) |
メモリのチャンネルスコープ
ナレッジベースの情報は、デフォルトでチャンネル単位に隔離されています。あるチャンネルのメモリが別のチャンネルに漏れることはありません。 常時適用したいルール(例: 特定チャンネルの行動指針)はalways_inject フラグで別管理します。管理者がこのフラグを設定したルールは、そのチャンネルのすべての会話に自動的にシステムプロンプトとして含まれます。
3 段階の重複防止
同じ内容を二重に登録しないための仕組みです。
この 3 段階のゲートにより、登録コストを通常 25〜40% 削減できます。
バージョン管理
既存書類の新しいバージョンをアップロード(例:policy.pdf → policy_v2.pdf)すると、以前のバージョンが ソフト削除 され、新しいバージョンに置き換わります。古いバージョンのチャンクはトランザクション処理で削除されるため、検索結果に出てきません。
- 置換理由 — バージョンが置き換えられた理由(例: 「ポリシー改訂」)を記録できます
- バージョン履歴の確認 — 書類をクリックすると、過去のバージョン・置換理由・更新者の一覧が表示されます
検索と引用
回答を生成する際、ナレッジベースは次の手順で情報を取得します:- BM25 キーワード検索(助詞を除去する日本語・韓国語トークナイザー)
- ベクトル意味検索(LanceDB)
- Reciprocal Rank Fusion で 2 つの結果を統合
- 再ランキング(任意、精度優先のシナリオで使用)
引用の表示方法
- Slack — 回答の下に出典カードを含むブロックとして表示
- ウェブチャット — 回答の横に引用カードが表示(ファイル名クリックでプレビュー)
- 方針 — 引用は インライン注釈ではなく永続メッセージ として記録 — 監査しやすく、編集で失われない
対応形式
Excel、CSV、PDF、HWP/HWPX、PPTX、DOCX、画像(OCR 付き)、動画(字幕付き)、音声、ZIP。詳細は ファイル処理 をご覧ください。引用と出典
引用の仕組みと活用方法。
ファイル処理
対応形式と処理内容の詳細。